Real-Time LLM Evaluation & Monitoring for AI Integrity
Argus is an end-to-end LLM evaluation and monitoring platform designed to help AI teams test, deploy, and continuously improve LLM-powered applications. By continuously assessing accuracy, bias, response consistency, and model drift, it ensures that deployed AI systems remain reliable, unbiased, and aligned with enterprise compliance standards.


Optimize And Benchmark Your LLM Applications
Argus is an AI monitoring system that tracks LLM performance in real time. It analyzes interaction logs, user inputs, model responses, and execution patterns, evaluating key metrics such as accuracy, latency, consistency, and policy alignment to ensure reliability.
Identifies prompt injections, adversarial attacks, and unauthorized data extraction attempts that could manipulate chatbot behavior or compromise sensitive information.
Ensures that responses adhere to ethical AI principles, regulatory requirements, and brand-specific policies, preventing misinformation, inappropriate outputs, and compliance violations.

Scans chatbot-generated content for offensive, biased, or harmful language, helping organizations maintain responsible AI interactions and a safe user experience.
Monitors chatbot activity for irregular patterns, flagging potential security breaches, system failures, or unexpected deviations in response behavior that require immediate intervention.

Evaluates chatbot responses based on relevance, coherence, and factual correctness, ensuring users receive high-quality, contextually appropriate information.
Captures and maintains conversation logs for accountability, debugging, and compliance reporting, enabling organizations to analyze interactions, refine chatbot logic, and meet audit requirements.

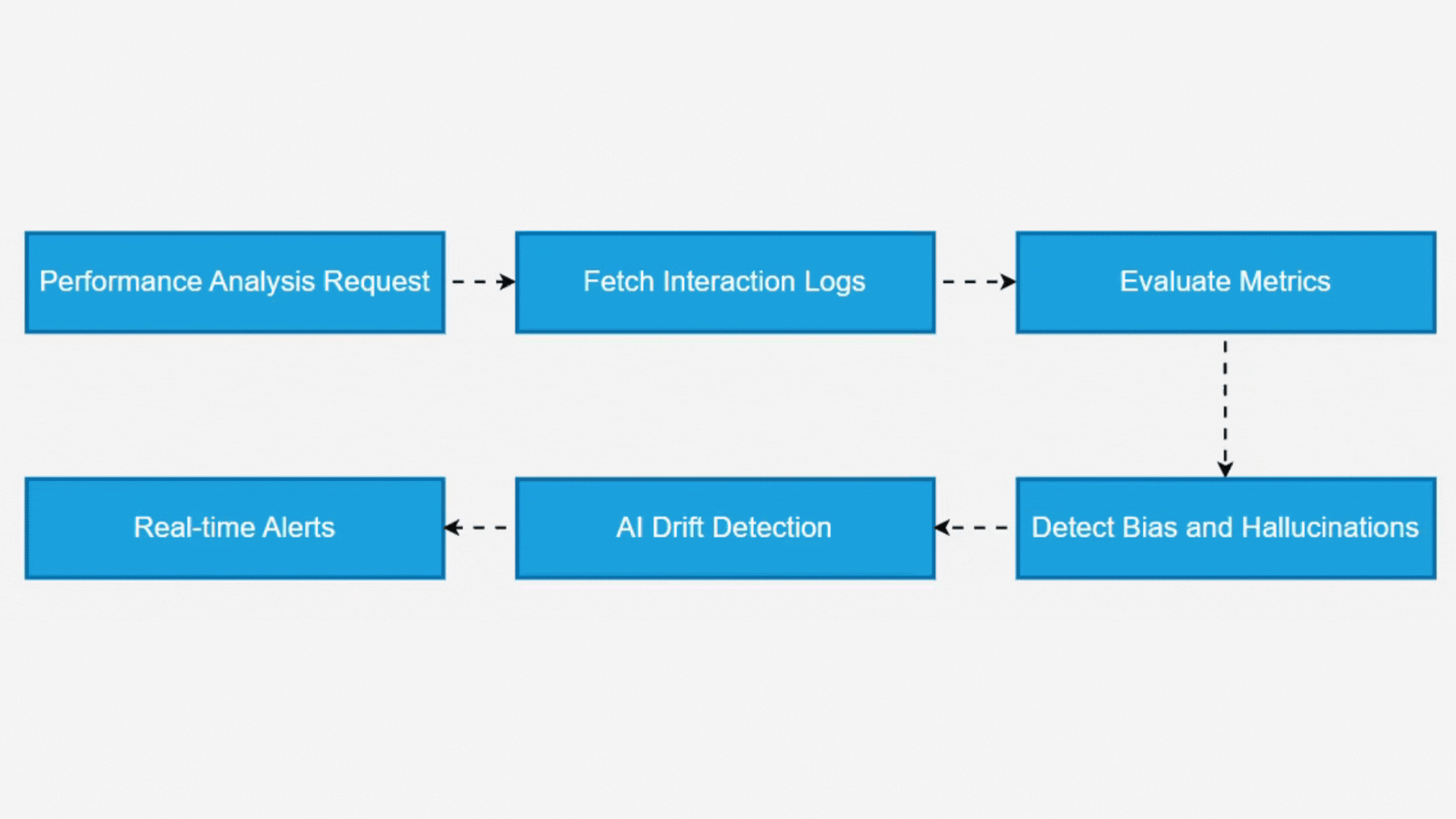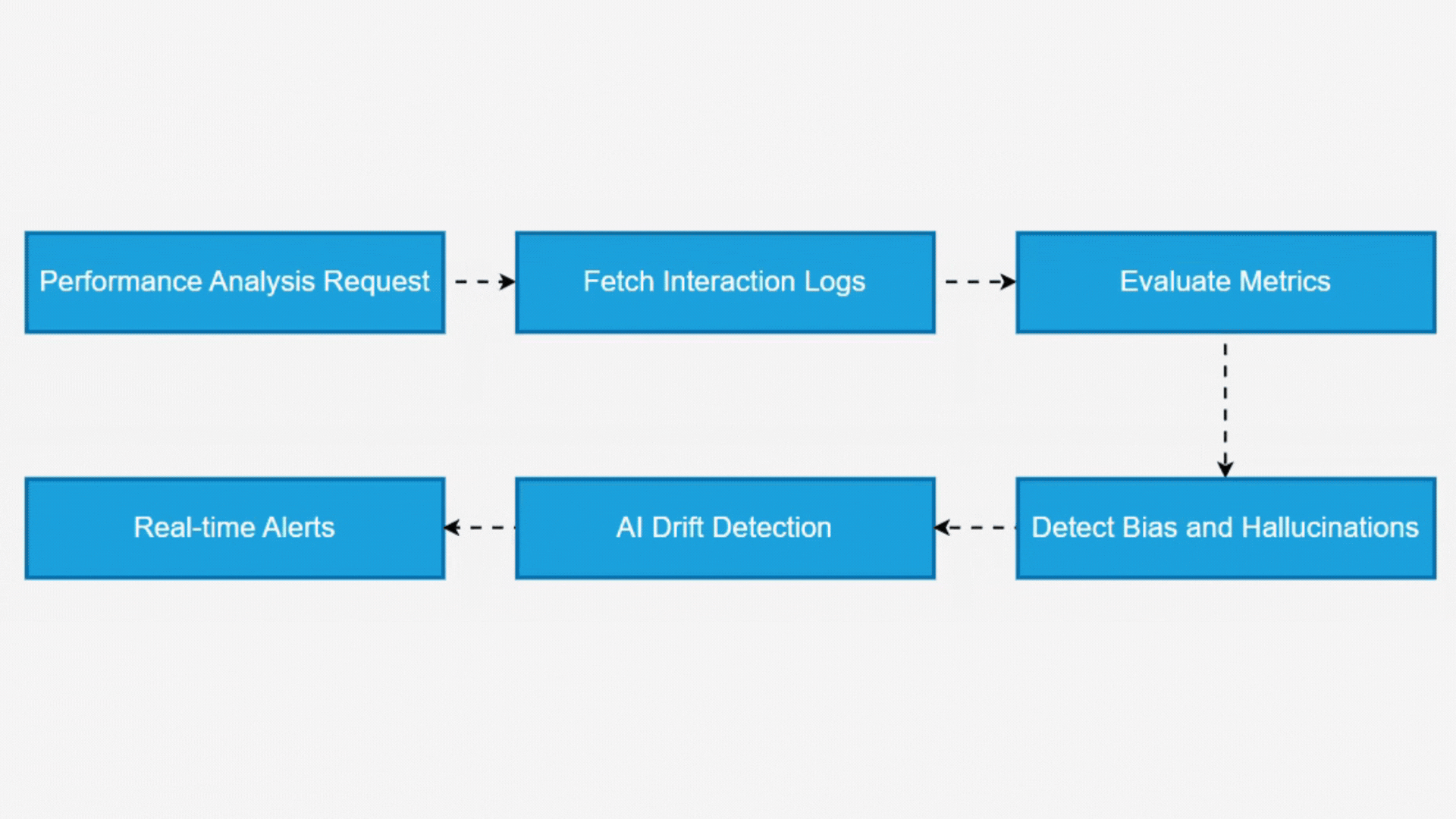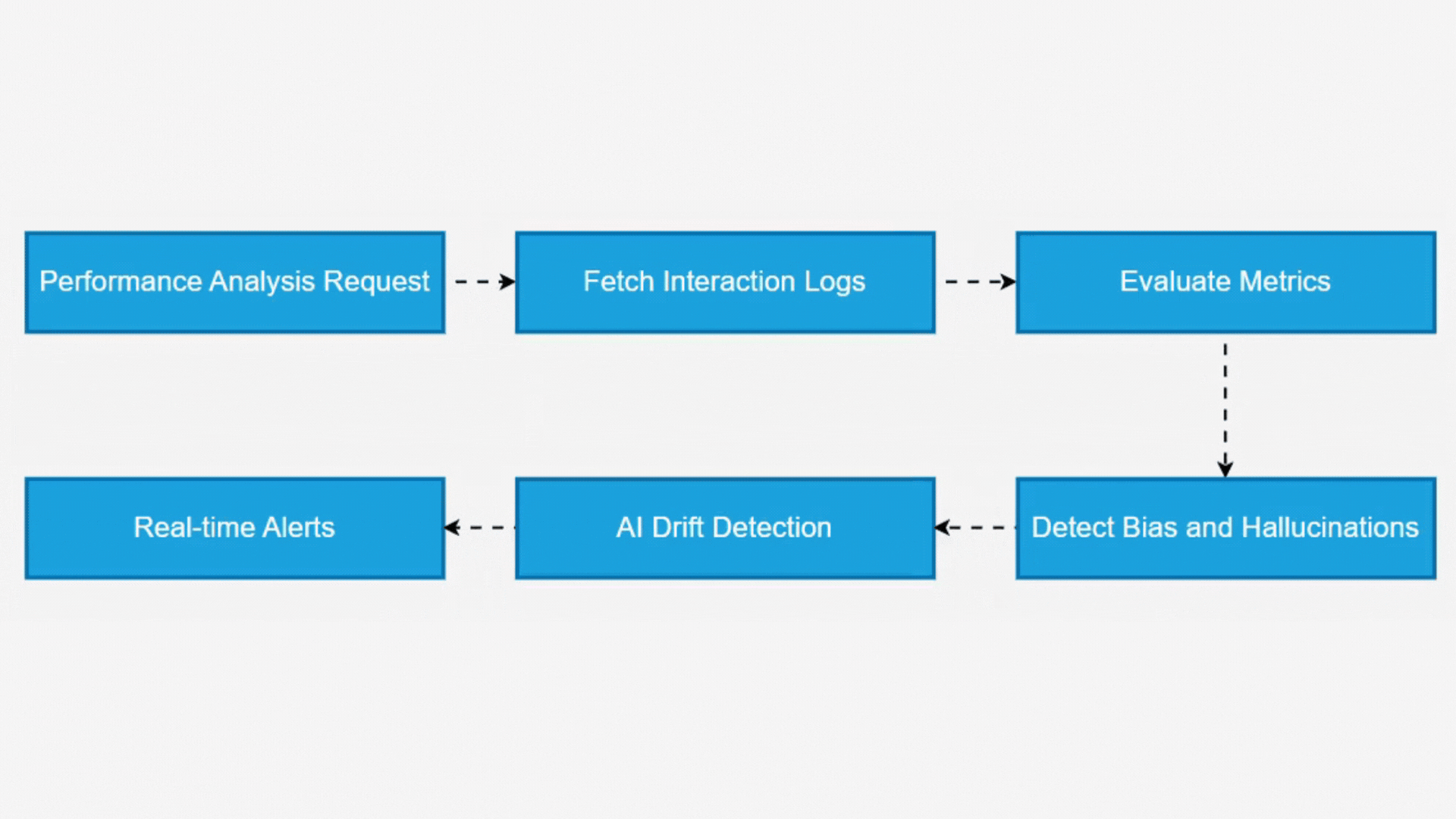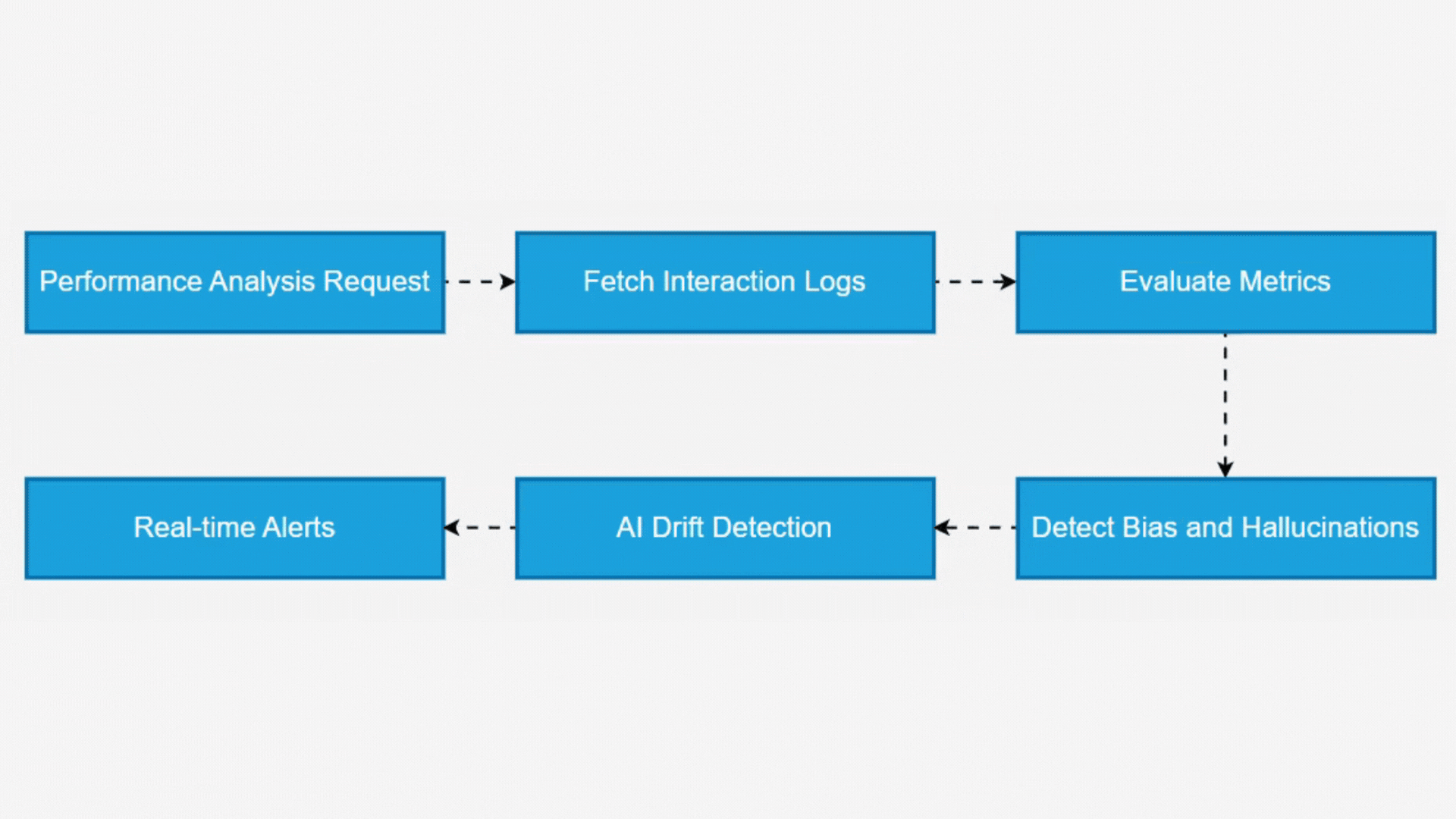
Through adaptive benchmarking algorithms, Argus identifies performance degradation, outliers, and unexpected model behavior, allowing teams to detect drift in AI decision-making over time. To ensure model reliability, it integrates bias detection, hallucination flagging, and anomaly identification mechanisms. The system applies linguistic pattern analysis, semantic verification, and contextual grounding techniques to assess AI-generated responses. By leveraging real-time deviation analysis, Argus proactively flags inconsistencies, biased content, and fabricated outputs, triggering alerts for immediate intervention.
How Argus Evaluates & Monitors LLMs
With AI’s Evolving Nature, Maintaining Oversight Is Critical. Argus Employs A Multi-Layered Evaluation And Monitoring Framework To Ensure Large Language Models (LLMs) Operate With Accuracy, Fairness, And Reliability.

AI Performance Analysis & Benchmarking
Argus initiates a comprehensive model evaluation, analyzing response accuracy, latency, consistency, and contextual relevance over a specific period. By comparing results against benchmarking standards, it identifies performance deviations and inefficiencies.

Bias & Fairness Detection in AI Outputs
The system continuously monitors responses for unintended bias by evaluating sentiment patterns, demographic-based disparities, and ethical concerns. If biases are detected, Argus flags inconsistencies and provides mitigation strategies.
Hallucination & False Information Detection
LLMs are prone to hallucinations, where AI generates fabricated or misleading information. Argus identifies such outputs using fact-checking models and contextual validation techniques, ensuring AI-generated content remains accurate and trustworthy.

Anomaly Detection & Real-Time Alerts
By leveraging AI drift detection, Argus monitors shifts in model behavior, alerting teams to performance degradation, non-compliant outputs, or ethical concerns in real time.


Start Your AI Observability
Journey With CyberGen
OUR RECENT BLOGS
Your Go-To Source for Tech Insights & Trends


 1.png)
Expanding Our Impact Through CyberGen Federal Services
At CyberGen, we are committed to driving innovation and operational excellence across industries. To extend our capabilities to the public sector, we created CyberGen Federal Services, a dedicated division focused exclusively on serving federal agencies and government contractors.
CyberGen Federal Services

CAGE Code : 9XHG2

CyberGen HelpDesk
CyberGen | One Team

Hey, I can help you with:
What AI solutions does CyberGen offer to enhance business operations? How can CyberGen's managed IT services improve my company's efficiency? What training programs are available through CyberGen Academy?